Learning to Assemble and to Generalize from Self-Supervised Disassembly
This is a crosspost from the official Google AI Blog.
Our physical world is full of different shapes, and learning how they are all interconnected is a natural part of interacting with our surroundings — for example, we understand that coat hangers hook onto clothing racks, power plugs insert into wall outlets, and USB cables fit into USB sockets. This general concept of “how things fit together’’ based on their shapes is something that we acquire over time and experience, and it helps to increase the efficiency with which we perform tasks, like assembling DIY furniture kits or packing gifts into a box. If robots could also learn “how things fit together,” then perhaps they could become more adaptable to new manipulation tasks involving objects they have never seen before, like reconnecting severed pipes, or building makeshift shelters by piecing together debris during disaster response scenarios.
To explore this idea, we worked with researchers from Stanford and Columbia Universities to develop Form2Fit, a robotic manipulation algorithm that uses deep neural networks to learn to visually recognize how objects correspond (or “fit”) to each other. To test this algorithm, we tasked a real robot to perform kit assembly, where it needed to accurately assemble objects into a blister pack or corrugated display to form a single unit. Previous systems built for this task required extensive manual tuning to assemble a single kit unit at a time. However, we demonstrate that by learning the general concept of “how things fit together,” Form2Fit enables our robot to assemble various types of kits with a 94% success rate. Furthermore, Form2Fit is one of the first systems capable of generalizing to new objects and kitting tasks not seen during training.

While often overlooked, shape analysis plays an important role in manipulation, especially for tasks like kit assembly. In fact, the shape of an object often matches the shape of its corresponding space in the packaging, and understanding this relationship is what allows people to do this task with minimal guesswork. At its core, Form2Fit aims to learn this relationship by training over numerous pairs of objects and their corresponding placing locations across multiple different kitting tasks – with the goal to acquire a broader understanding of how shapes and surfaces fit together. Form2Fit improves itself over time with minimal human supervision, gathering its own training data by repeatedly disassembling completed kits through trial and error, then time-reversing the disassembly sequences to get assembly trajectories. After training overnight for 12 hours, our robot learns effective pick and place policies for a variety of kits, achieving 94% assembly success rates with objects and kits in varying configurations, and over 86% assembly success rates when handling completely new objects and kits.
Data-Driven Shape Descriptors For Generalizable Assembly
The core of Form2Fit is a two-stream matching network that learns to infer orientation-sensitive geometric pixel-wise descriptors for objects and their target placement locations from visual data. These descriptors can be understood as compressed 3D point representations that encode object geometry, textures, and contextual task-level knowledge. Form2Fit uses these descriptors to establish correspondences between objects and their target locations (i.e., where they should be placed). Since these descriptors are orientation-sensitive, they allow Form2Fit to infer how the picked object should be rotated before it is placed in its target location.
Form2Fit uses two additional networks to generate valid pick and place candidates. A suction network gets fed a 3D image of the objects and generates pixel-wise predictions of suction success. The suction probability map is visualized as a heatmap, where hotter pixels indicate better locations to grasp the object at the 3D location of the corresponding pixel. In parallel, a place network gets fed a 3D image of the target kit and outputs pixel-wise predictions of placement success. These, too, are visualized as a heatmap, where higher confidence values serve as better locations for the robot arm to approach from a top-down angle to place the object. Finally, the planner integrates the output of all three modules to produce the final pick location, place location and rotation angle.
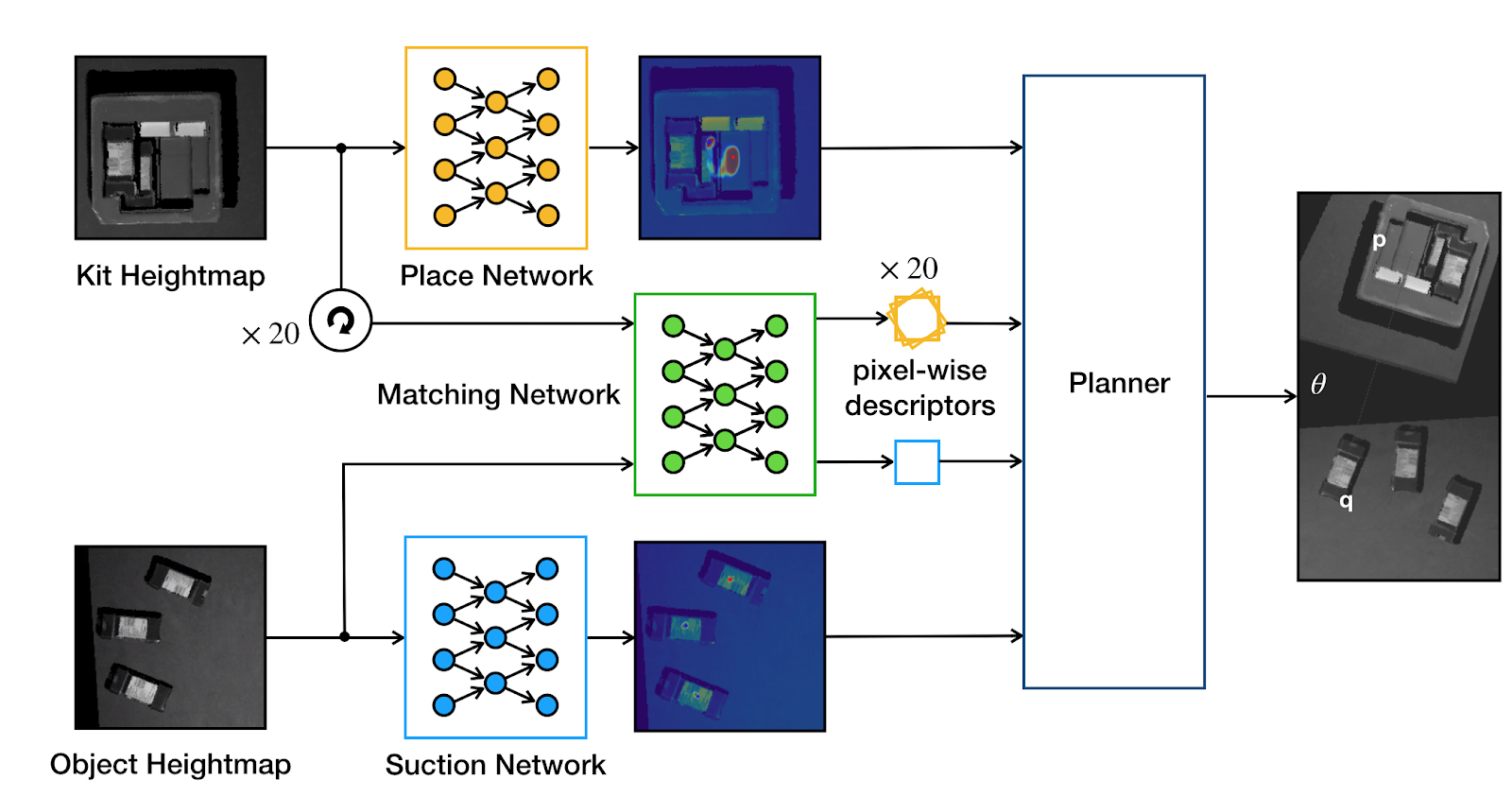
Learning Assembly from Disassembly
Neural networks require large amounts of training data, which can be difficult to collect for tasks like assembly. Precisely inserting objects into tight spaces with the correct orientation (e.g., in kits) is challenging to learn through trial and error, because the chances of success from random exploration can be slim. In contrast, disassembling completed units is often easier to learn through trial and error, since there are fewer incorrect ways to remove an object than there are to correctly insert it. We leveraged this difference in order to amass training data for Form2Fit.

Our key observation is that in many cases of kit assembly, a disassembly sequence – when reversed over time – becomes a valid assembly sequence. This concept, called time-reversed disassembly, enables Form2Fit to train entirely through self-supervision by randomly picking with trial and error to disassemble a fully-assembled kit, then reversing that disassembly sequence to learn how the kit should be put together.
Generalization Results
The results of our experiments show great potential for learning generalizable policies for assembly. For instance, when a policy is trained to assemble a kit in only one specific position and orientation, it can still robustly assemble random rotations and translations of the kit 90% of the time.

We also find that Form2Fit is capable of tackling novel configurations it has not been exposed to during training. For example, when training a policy on two single-object kits (floss and tape), we find that it can successfully assemble new combinations and mixtures of those kits, even though it has never seen such configurations before.

Furthermore, when given completely novel kits on which it has not been trained, Form2Fit can generalize using its learned shape priors to assemble those kits with over 86% assembly accuracy.

What Have the Descriptors Learned?
To explore what the descriptors of the matching network from Form2Fit have learned to encode, we visualize the pixel-wise descriptors of various objects in RGB colorspace through use of an embedding technique called t-SNE.
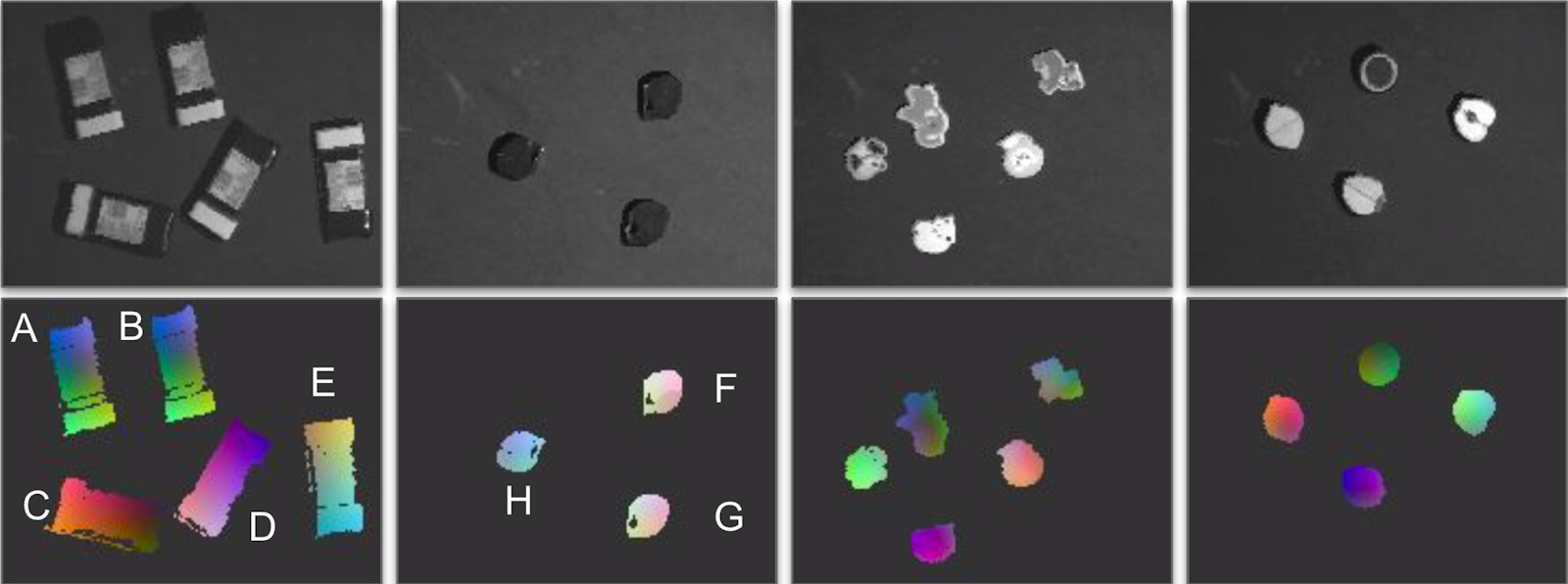
We observe that the descriptors have learned to encode (a) rotation — objects oriented differently have different descriptors (A, C, D, E) and (H, F); (b) spatial correspondence — same points on the same oriented objects share similar descriptors (A, B) and (F, G); and (c) object identity — zoo animals and fruits exhibit unique descriptors (columns 3 and 4).
Limitations & Future Work
While Form2Fit’s results are promising, its limitations suggest directions for future work. In our experiments, we assume a 2D planar workspace to constrain the kit assembly task so that it can be solved by sequencing top-down picking and placing actions. This may not work for all cases of assembly – for example, when a peg needs to be precisely inserted at a 45 degree angle. It would be interesting to expand Form2Fit to more complex action representations for 3D assembly.
You can learn more about this work and download the code from our GitHub repository.
Acknowledgments
This research was done by Kevin Zakka, Andy Zeng, Johnny Lee, and Shuran Song (faculty at Columbia University), with special thanks to Nick Hynes, Alex Nichol, and Ivan Krasin for fruitful technical discussions; Adrian Wong, Brandon Hurd, Julian Salazar, and Sean Snyder for hardware support; Ryan Hickman for valuable managerial support; and Chad Richards for helpful feedback on writing.