Deriving the Gradient for the Backward Pass of Batch Normalization
I recently sat down to work on assignment 2 of Stanford’s CS231n. It’s lengthy and definitely a step up from the first assignment, but the insight you gain is tremendous.
Anyway, at one point in the assignment, we were tasked with implementing a Batch Normalization layer in our fully-connected net which required writing a forward and backward pass.
The forward pass is relatively simple since it only requires standardizing the input features (zero mean and unit standard deviation). The backwards pass, on the other hand, is a bit more involved. It can be done in 2 different ways:
- staged computation: we can break up the function into several parts, derive local gradients for them, and finally multiply them with the chain rule.
- gradient derivation: basically, you have to do a “pen and paper” derivation of the gradient with respect to the inputs.
It turns out that second option is faster, albeit nastier and after struggling for a few hours, I finally got it to work. This post is mainly a clear summary of the derivation along with my thought process, and I hope it can provide others with the insight and intuition of the chain rule. There is a similar tutorial online already (but I couldn’t follow along very well) so if you want to check it out, head over to Clément Thorey’s Blog.
Finally, I’ve summarized the original research paper and accompanied it with a small numpy implementation which you can view on my Github. With that being said, let’s jump right into the blog.
Notation
Let’s start with some notation.
- BN will stand for Batch Norm.
- represents a layer upwards of the BN one.
- is the linear transformation which scales by and adds .
- is the normalized inputs.
- is the batch mean.
- is the batch variance.
The below table shows you the inputs to each function and will help with the future derivation.

Goal: Find the partial derivatives with respect to the inputs, that is , and .
Methodology: derive the gradient with respect to the centered inputs (which requires deriving the gradient w.r.t and ) and then use those to derive one for .
Chain Rule Primer
Suppose we’re given a function where and . Then to determine the value of and we need to use the chain rule which says that:
That’s basically all there is to it. Using this simple concept can help us solve our problem. We just have to be clear and precise when using it and not get lost with the intermediate variables.
Partial Derivatives
Here’s the gist of BN taken from the paper.

We’re gonna start by traversing the table from left to right. At each step we derive the gradient with respect to the inputs in the cell.
Cell 1

Let’s compute . It actually turns out we don’t need to compute this derivative since we already have it - it’s the upstream derivative dout given to us in the function parameter.
Cell 2

Let’s work on cell 2 now. We note that is a function of three variables, so let’s compute the gradient with respect to each one.
Starting with and using the chain rule:
Notice that we sum from because we’re working with batches! If you’re worried you wouldn’t have caught that, think about the dimensions. The gradient with respect to a variable should be of the same size as that same variable so if those two clash, it should tell you you’ve done something wrong.
Moving on to we compute the gradient as follows:
and finally :
Up to now, things are relatively simple and we’ve already done 2/3 of the work. We can’t compute the gradient with respect to just yet though.
Cell 3

We start with and notice that is a function of , therefore we need to add its contribution to the partial - (I’ve highlighted the missing partials in red):
Let’s compute the missing partials one at a time.
From
we compute:
and from
we calculate:
We’re missing the partial with respect to and that is our next variable, so let’s get to it and come back and plug it in here.
Ok so in the expression of the partial:
let’s compute in more detail. I’m gonna rewrite to make its derivative easier to compute:
is a constant therefore:
With all that out of the way, let’s plug everything back in our previous partial!
Thus we have:
We finally arrive at the last variable . Again adding the contributions from any parameter containing we obtain:
The missing pieces are super easy to compute at this point.
That’s it, our final gradient is
Note the following trick
With that in mind, let’s plug in the partials and see if we can simplify the expression some more.
Finally, we factorize by the sigma + epsilon factor and obtain:
Recap
For organizational purposes, let’s summarize the main equations we were able to derive. Using , we obtain the gradient with respect to our inputs:
Python Implementation
Here’s an example implementation using the equations we derived. dx is 88 characters long so I’m still wondering how the course instructors were able to write it less than 80 - maybe shorter variable names?
def batchnorm_backward(dout, cache):
N, D = dout.shape
x_mu, inv_var, x_hat, gamma = cache
# intermediate partial derivatives
dxhat = dout * gamma
# final partial derivatives
dx = (1. / N) * inv_var * (N*dxhat - np.sum(dxhat, axis=0)
- x_hat*np.sum(dxhat*x_hat, axis=0))
dbeta = np.sum(dout, axis=0)
dgamma = np.sum(x_hat*dout, axis=0)
return dx, dgamma, dbeta
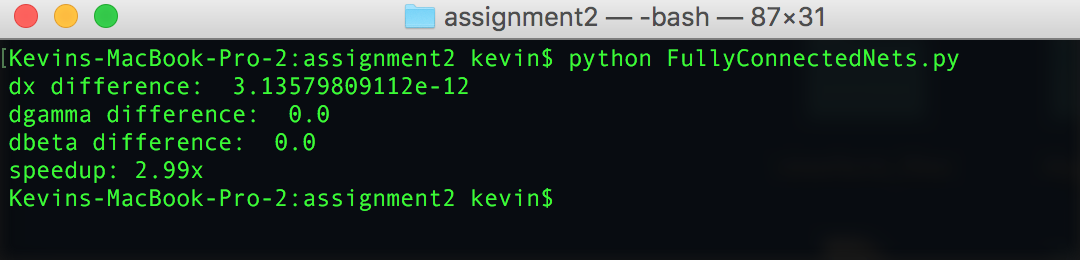
This version of the batchnorm backward pass can give you a significant boost in speed. I timed both versions and got a superb threefold increase in speed:
Conclusion
In this blog post, we learned how to use the chain rule in a staged manner to derive the expression for the gradient of the batch norm layer. We also saw how a smart simplification can help significantly reduce the complexity of the expression for dx. We finally implemented it the backward pass in Python using the code from CS231n. This version of the function resulted in a 3x speed increase!
If you’re interested in the staged computation method, head over to Kratzert’s nicely written post.
Cheers!